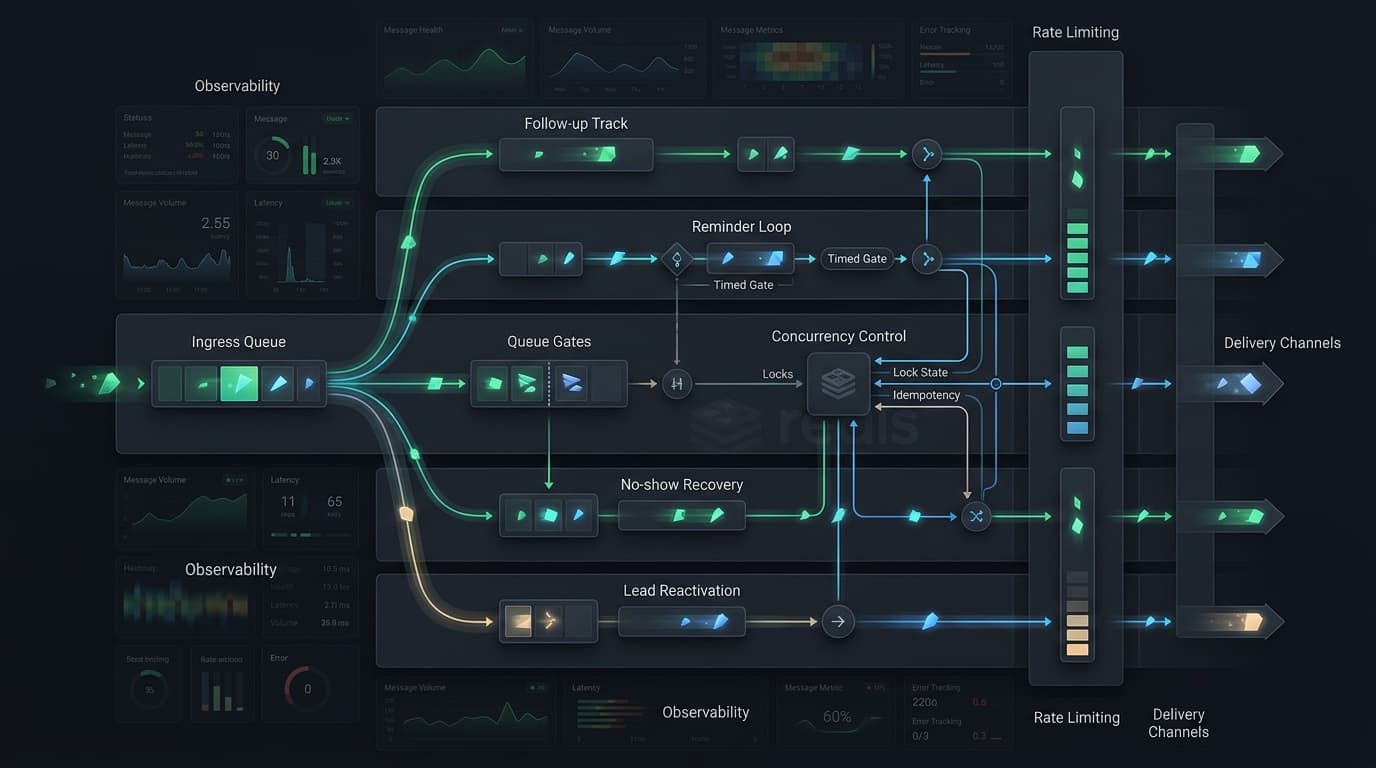
Overview
I designed and implemented a backend messaging orchestration system for CRM-driven WhatsApp workflows.
The goal was not just to send messages through an API. The real challenge was to turn a fragmented automation setup into something explicit, trackable, operationally safer, and easier to evolve over time.
The result was a flow-based architecture covering the full lead and meeting lifecycle: welcome messages, follow-ups, booking confirmations, reminders, no-show recovery, rescheduling, sales follow-up, and reactivation of stalled leads.
The problem
The existing setup had the usual symptoms of a system that grew in production before anyone had time to step back and tame it:
- multiple legacy automation paths
- overlapping responsibilities
- inconsistent tracking
- brittle status-driven logic
- operational risk around duplicate sends, retries, and scheduling
- poor visibility into what had happened for a specific lead
The problem was not the messaging provider itself. The problem was the lack of a clear orchestration model around it.
The solution
I introduced a more structured architecture centered around a dedicated messaging service, explicit flow jobs, scheduled dispatchers, shared flow tracking, and send guards.
Instead of treating each automation as an isolated script, the system treated messaging as a coordinated workflow problem.
That meant designing for the real-world concerns that actually matter in production:
- state transitions
- queueing
- retries
- rate limits
- idempotency
- message timing windows
- reply-aware behavior
- migration from legacy code without breaking business continuity
What I built
1. Centralized message sending
I consolidated outbound WhatsApp sending behind a dedicated service layer instead of letting direct API calls leak across the codebase.
This created a cleaner boundary for:
- channel resolution
- template resolution
- request handling
- tracking
- logging
2. Flow-based architecture
I implemented explicit flow jobs and dispatcher commands for the main lifecycle stages:
- welcome flow
- follow-up flow
- booking confirmations
- meeting reminders
- no-show recovery
- rescheduling flow
- post-meeting sales follow-up
- lead rewarming for stuck or aging records
Each flow had its own rules for timing, eligibility, progression, and state updates.
3. Tracking and state management
A major part of the work was making the system observable and predictable.
I added tracking for:
- per-lead flow progress
- per-meeting flow progress where needed
- message attempts and responses
- skipped steps and completion markers
- idempotency keys to prevent duplicate sends
That made it possible to inspect a lead and answer the question that really matters in ops: what happened, when, and why?
4. Reliability controls
Because this was a real communication system rather than a toy demo, reliability concerns had to be first-class.
I built around:
- queued jobs
- retry/backoff behavior
- staggered dispatch timing
- rate-limit-aware flow behavior
- Redis-based caching and coordination for concurrent send control
- safe progression logic
- duplicate-send protection
This reduced the risk of fragile cron behavior or overlapping dispatches causing message spam.
5. Migration-safe coexistence with legacy automations
One of the trickiest parts was that the new architecture had to coexist with older automation paths during transition.
So the design was not just about greenfield elegance. It also had to be pragmatic:
- understand legacy tracking data
- tolerate inconsistent status variants
- provide fallback behavior during migration
- create a path to gradually deprecate older automation logic
That kind of work is less glamorous than clean-slate architecture, but it is much closer to real engineering.
Why this project matters
This project is a good example of the kind of backend work I like doing:
- taking a messy, high-friction system
- making the boundaries explicit
- designing around operational reality, not diagrams
- improving maintainability without pretending the legacy world does not exist
The value was not just in “automating messages.”
The value was in turning a fragile collection of automations into a workflow system a team could reason about, debug, and extend with less fear.
Technical highlights
- Laravel / PHP backend
- queue-based job execution
- scheduled dispatchers and cron-triggered flows
- CRM-driven workflow logic
- API integration with WhatsApp messaging infrastructure
- Redis-backed caching and concurrent dispatch coordination
- per-lead and per-meeting flow tracking
- idempotency guards for safe retries
- operational logging and message attempt persistence
- migration support from legacy automation paths
Key takeaways
A lot of backend systems fail not because the code cannot call an API, but because the workflow boundary is never defined clearly enough.
This project reinforced a pattern I trust:
when communication logic becomes business-critical, it should be modeled as a system, not left as a pile of scripts.
That usually means a few boring but powerful things:
- one clear service boundary
- explicit workflow state
- controlled scheduling
- strong observability
- migration discipline
Boring architecture wins.
If I extended it further
If I were evolving the system further, I would focus on:
- a stronger operator-facing dashboard for flow state and interventions
- tighter analytics around flow outcomes and reply behavior
- continued removal of legacy fallback logic once the migration is complete
- clearer business reporting on lifecycle messaging effectiveness
Final note
This was not a “simple integration.”
It was a backend workflow design problem hiding behind a messaging API.
That is exactly the kind of problem I enjoy: the ones where reliability, product behavior, state modeling, and operational clarity all collide in the same system.