AI tools become genuinely useful long before they become operationally trustworthy.
That was the real issue I kept running into.
The problem was not whether an agent could generate a decent answer, summarize a document, draft copy, or help with code. It could. The problem was what happened when the work stopped being a single task and became an ongoing collaboration problem across product, UX, engineering, writing, and coordination.
At that point, ad-hoc AI usage started showing the same pattern over and over: impressive early, messy later.
This article is about that shift, and about what worked better instead.
The real problem was not “how do we use AI?”
The real problem was this:
how do we make AI-assisted engineering collaboration reliable enough to support real product and implementation work?
That sounds more serious than “using AI well,” because it is.
A lot of AI usage stays trapped in the tool layer. People ask what model to use, how good the prompts are, or whether an agent can complete a task end to end.
Those questions matter, but they miss the operating-model problem.
Once the work spans multiple domains, multiple iterations, and multiple stakeholders, the quality of the system around the model starts to matter more than the novelty of the model itself.
That is where the trouble started.
Why the one-generalist-agent model broke down
At first, a single generalist agent feels efficient.
You can keep everything in one place. Product clarification, design thinking, implementation help, copywriting, planning, and coordination all sit in the same thread. The agent remembers “the whole picture.” There is very little setup overhead. The experience feels fluid.
Then the work becomes real.
As soon as multiple domains are moving at once, that convenience starts creating failure modes:
- ownership becomes fuzzy
- outputs become inconsistent
- handoffs get weak
- one thread accumulates too much mixed context
- review happens late, vaguely, or only after several things have already drifted
- the agent starts sounding competent across everything while being shallow or unstable in the places that matter most
The problem gets worse when memory and continuity are also concentrated in that one generalist setup.
At small scale, that feels like efficiency. At larger scale, it becomes fragility.
A single agent carrying product context, UX logic, implementation state, editorial decisions, and coordination history at the same time is not just overloaded. It also becomes a weak boundary system. Concerns bleed into each other. Recall becomes less reliable. Different kinds of work start contaminating each other.
That was the real turning point for me.
The issue was not “AI memory is imperfect.” The issue was that memory, role, ownership, and continuity were being left undesigned.
Ad-hoc collaboration works until it starts costing you
This is the pattern I now distrust the most in AI-assisted work.
Ad-hoc usage often feels great in the first phase because it compresses setup. You can ask for almost anything, the tool gives you something plausible, and the interaction feels productive.
But the cost shows up later:
- a product clarification quietly becomes an architecture assumption
- a UX idea turns into implementation direction without enough scrutiny
- a copy draft inherits technical framing that should never have reached the final wording
- coordination gets absorbed into whoever happens to have the most context, rather than into a clear operating role
- human review becomes cleanup instead of guidance
None of this usually fails in one dramatic way. It fails by adding friction, ambiguity, and hidden correction work.
That is why I stopped thinking about the problem as “better prompting” and started thinking about it as workflow design.
What worked better: a governed collaboration model
The better model was not “more autonomous AI.”
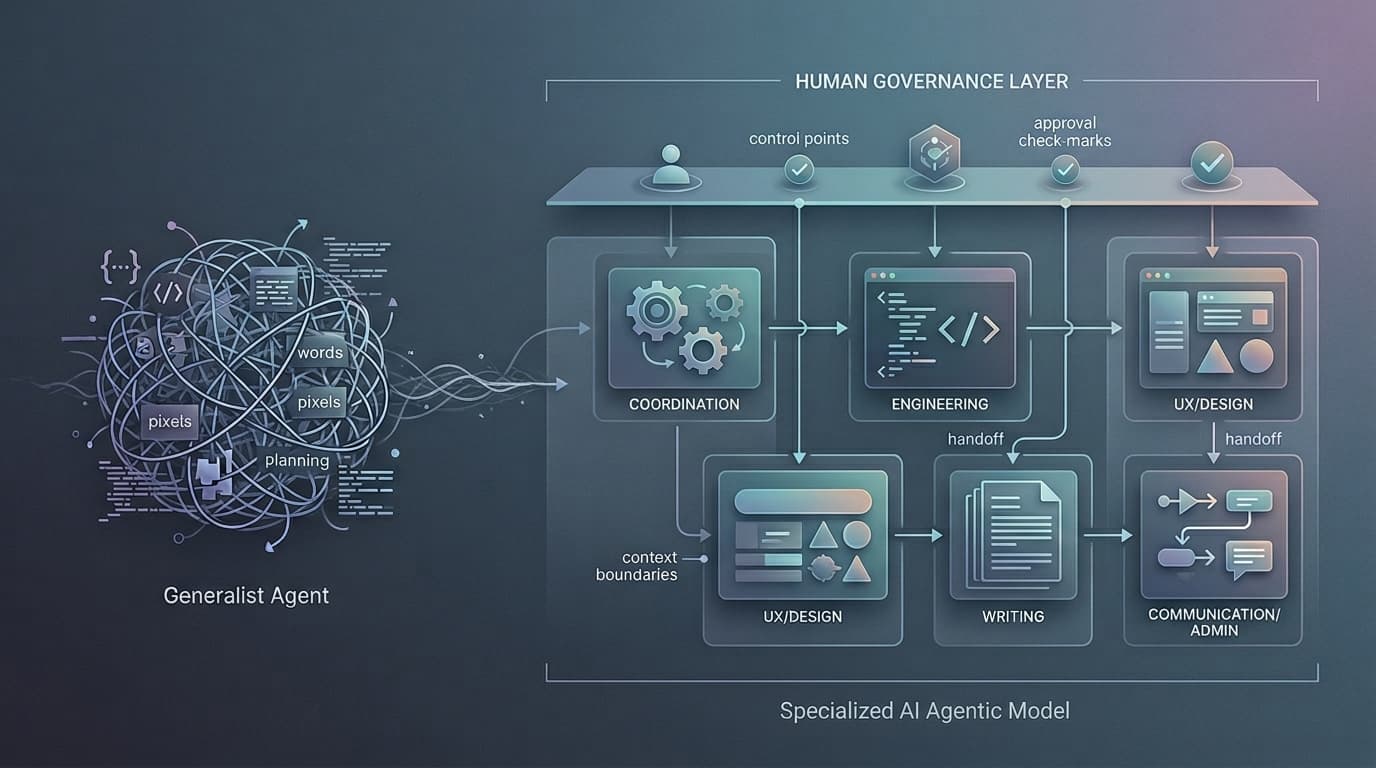
It was a governed collaboration system with explicit roles, scoped responsibilities, controlled handoffs, memory discipline, and human approval points.
In practice, that meant moving away from one oversized generalist thread and toward a specialist-role operating model.
The roles were simple and pragmatic:
- Nemo for coordination, product management, and primary contact handling
- Jinx for engineering implementation, systems architecture, and software development
- Vi for product and UX systems design
- Escriba for copywriting and messaging
- Sancho for communication and administrative support
- tp as final decision-maker and approval authority
The names themselves are not the important part. The operating model is.
What mattered was that each role had a lane.
This did a few useful things immediately:
- reduced role blending
- improved ownership clarity
- made outputs easier to evaluate
- made delegation more intentional
- created better conditions for parallel work
- gave human review a clearer place in the flow
Instead of asking one agent to play six jobs at once, the workflow started acting more like a structured collaboration system.
The system needed rules, not just roles
Role naming alone is not enough. If the workflow is still vague, you just end up with branded ambiguity.
What made the model actually useful was the operational discipline around it.
1. Explicit ownership
Each role had a defined responsibility boundary.
Product clarification stayed with coordination. UX system thinking stayed with design. Implementation stayed with engineering. Copy stayed with writing. Communication support stayed separate from core technical and product work.
That sounds obvious, but it matters. Clear lanes reduce noise and make it easier to inspect whether an output is good for the job it was supposed to do.
2. Controlled handoffs
Work did not move just because one role generated text.
Handoffs were explicit. A coordination layer could gather the right context, delegate to the appropriate specialist, and bring the result back for review, synthesis, or approval.
That made parallel work possible without everything collapsing into one confused thread.
3. Human approval at meaningful points
Important decisions stayed under human control.
That included public-facing output, architecture direction, implementation decisions with real consequences, and anything that affected external communication or commitment.
This was not about distrust. It was about accountability and timing. Human review works better when it is part of the operating model, not an improvised rescue step at the end.
4. Memory and context as first-class concerns
Context was documented and scoped instead of being left to float inside one oversized conversation.
This improved continuity, reduced context pollution, and made it easier to preserve the right information in the right place. It also reduced the chance that unrelated workstreams would distort each other simply because they shared a memory container.
5. Verification over autonomy theater
Outputs that affected implementation or external-facing work were expected to go through review, validation, inspection, or direct checking.
The goal was not to simulate independence. The goal was to create a workflow that could support real work without turning quality control into wishful thinking.
Why this worked better in practice
The governed model worked better because it replaced vague flexibility with usable structure.
That structure improved day-to-day work in concrete ways:
- ownership became clearer
- specialist outputs became more reliable
- review happened earlier and more deliberately
- context stayed better contained
- product, UX, engineering, and communication stayed more aligned
- parallel work became easier to coordinate
- less hidden correction work accumulated in the background
Just as importantly, it changed the standard for what “good AI usage” meant.
The goal stopped being clever prompting or impressive one-shot generation. The goal became operational reliability: better handoffs, stronger review, cleaner context boundaries, and outputs that held up better under real use.
That is a much less glamorous story than “autonomous agents,” but it is the one I trust.
Coordination turned out to matter as much as generation
One thing this work made very clear is that generation quality is only part of the picture.
A lot of the real leverage came from coordination.
Who routes the task? Who owns the question? Who decides whether the output is done, needs revision, or should go to another specialist? What context should be preserved, and what should not leak across workstreams? Where does human judgment need to intervene?
Those questions are not side details. They are the system.
If coordination is weak, even strong generation gets wasted. If coordination is strong, AI becomes much more useful because it is being used inside a workflow that can absorb, verify, and redirect outputs properly.
That is one of the biggest lessons I would carry into any serious AI-assisted operating model.
The highest leverage was not more autonomy
This is probably the cleanest summary of what changed my view.
The highest leverage did not come from making AI more autonomous.
It came from structuring collaboration better between human judgment and specialized AI roles.
That meant:
- treating AI workflows as operational systems
- designing for boundaries instead of convenience
- deciding where review belongs before outputs drift
- making memory and continuity part of the architecture
- valuing handoffs and coordination as much as raw generation
In other words, the useful shift was not from “human work” to “AI work.” It was from vague assistance to governed collaboration.
What I would tell teams trying to do this seriously
If a team is using AI across product, UX, engineering, and communication work, I would not start by asking how to make a single agent more powerful.
I would start with these questions:
- what roles actually exist in the work?
- where are the ownership boundaries?
- what context should stay shared, and what should stay scoped?
- where do handoffs happen?
- where does approval need to happen?
- what should be verified, and by whom?
Those answers matter more than whether the system sounds impressive in a demo.
If the workflow is ad-hoc, the problems will eventually show up as ambiguity, drift, correction work, and inconsistent quality. If the workflow is governed, AI becomes much more useful because the collaboration around it is doing its job.
Final thought
I do not think the interesting question is whether one agent can do many things.
It usually can, at least superficially.
The more important question is whether AI-assisted collaboration can support real work without quietly making ownership, review, continuity, and execution worse.
For me, the answer improved once I stopped treating AI as a clever generalist and started treating collaboration as a system that needed design.
That shift — from one generalist agent to a governed collaboration model — is what made the workflow more reliable, more legible, and more useful in practice.