A flag that kept appearing and vanishing across identical runs
I was testing JD Analyzer, a small LLM pipeline I run as part of my own job search. You paste in a job description and it returns a structured fit analysis — extracted fields, a score, and a set of risk flags with evidence. The flags are the part that earns its keep: they're what tell me, at a glance, whether a role trips one of my deal-breakers.
I had a real agentic-AI role I'd run through it — a Spanish "Agentic AI Engineer" posting, genuinely interesting, exactly my lane. And it would not hold still. One run, clean. Next run, same paste, a yellow flag. Run again, clean. Same input. Same code. temperature: 0 on every call.
So I did the thing you do: I went hunting for the change I'd made. A prompt edit, a stray non-zero temperature, a race in the parallel calls, something. I diffed. I re-ran. I checked git. There was no change. The input was byte-for-byte identical and the output was not.
That bug shouldn't exist. The whole reason temperature=0 is in there is so this bug doesn't exist. Which is exactly where the story gets interesting — because the textbook reason it shouldn't exist is almost true, and the "almost" is the entire piece.
The comfortable lie
Here's the story everyone learns, and it's the one I was leaning on:
temperature=0makes sampling greedy. The model takes the argmax of the logits at every step — always the single highest-probability token. No sampling, no randomness. Same input, same weights, same output. Deterministic.
That's the textbook account, and it's almost right, which is what makes it dangerous. It describes the decoding correctly. temperature=0 really does collapse sampling to argmax; nobody is rolling dice. If your mental model stops there, you conclude that any variation must be a bug in your code — so you go hunting for a code change, find nothing, and start to question your own sanity. I did.
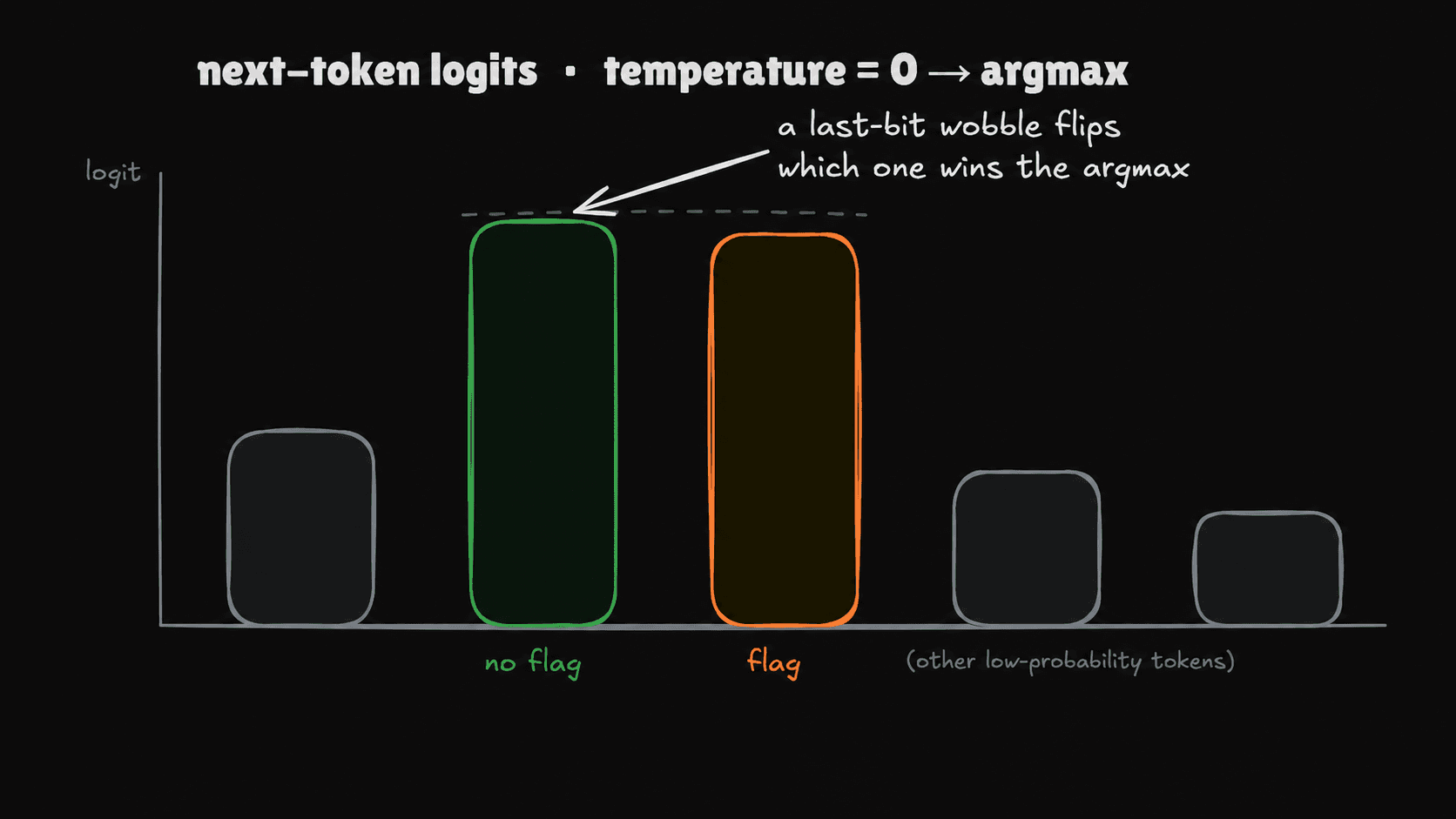
In fact, at temperature=0 there isn't even a softmax in the loop. The usual recipe — scale the logits by 1/T, softmax them into probabilities, sample one — breaks at T=0, because dividing by zero is undefined. So implementations special-case it: skip the softmax and the sampling entirely, and read the argmax straight off the raw logits. Softmax is monotonic anyway — it never changes which logit is largest — so at T=0 it's dead weight and the decoder drops it. Which quietly sharpens the whole problem: there's no probability distribution being sampled, just a ranking being read — and a ranking is exactly the kind of thing a tiny numerical wobble can invert.
The flaw isn't in the decoding rule. It's in the assumption that the logits feeding that argmax are themselves bit-for-bit identical from one call to the next. In production, they are not.
Why production inference breaks it
This is the part worth getting exactly right, because it's where the "temp 0 is random" hand-wave fails and the real mechanism lives.
The variation is not randomness. The model isn't sampling differently. The logits themselves come out slightly different from one call to the next — and the cause is batch-invariance, or rather the lack of it.
When you hit a hosted model, your request doesn't run alone. The server batches your prompt with whatever other traffic arrives in that same window to keep the GPU busy. The batch composition is therefore non-deterministic from your point of view — it depends on what milliseconds your request landed in. And here's the catch: the inference kernels are not batch-invariant. The order in which the GPU sums up a reduction depends on the batch shape, and floating-point addition is not associative — (a + b) + c is not bit-identical to a + (b + c) once rounding enters. Change the reduction order, and the logits differ in their last few bits.
For a Mixture-of-Experts model, there's a second source on top: expert routing can depend on the batch, so two runs can route the same token through different experts and diverge earlier and harder.
Almost always, none of this matters. A logit difference in the fifteenth bit changes nothing you'd ever observe. But on a token where the top two candidates are nearly tied, that last-bit wobble is enough to swap which one wins the argmax. The decoding is still perfectly greedy. It's greedily picking from logits that quietly moved.
This is exactly the problem Thinking Machines mapped out in Defeating Nondeterminism in LLM Inference (2025): reproducibility is a property of the serving stack, not a gift of the sampler. You can fix it at that layer — batch-invariant kernels exist, and dedicated inference setups (the post ships them for vLLM) can make runs bit-reproducible. But on hosted inference behind an API, you don't own the serving stack — so the application-layer fix is the one actually available to you. Which is where the rest of this post goes.
The nuance that actually matters: it's not random, it's borderline
Here is the part that turned this from a frustrating ghost into a fixable bug.
It is not random. If it were, every output would be a coin toss and the tool would be useless. It isn't. The overwhelming majority of inputs are rock-stable across runs — a JD that clearly demands on-site work in another country flags every single time; a JD that's clearly clean stays clean every single time. Run those a hundred times and you get the same answer a hundred times.
Only inputs sitting on a decision boundary flip. The flicker is concentrated exactly where the model's confidence between two outcomes is near-tied — where "flag" and "no flag" sit a hair apart in logit space. Everywhere else, the last-bit wobble is nowhere near enough to change the winner.
So the real question isn't "why is temp 0 random" (it isn't). It's "why is this particular input sitting on the knife's edge?" — and when I looked, the answer was my own fault. I had written an over-engineered prompt rule, a verbose, hedge-laden instruction for that class of concern, and it had taken a genuinely ambiguous case and shoved it right onto the boundary. The model wasn't confused by the JD. It was confused by me.
Fix part one: get off the boundary
The first fix isn't clever. It's the unglamorous one: stop manufacturing borderline cases.
I reverted the verbose rule back to a tight, plain instruction. That doesn't make the floating-point physics go away — the kernels are still not batch-invariant — but it moves genuinely-decidable inputs away from the tie zone, so the last-bit wobble no longer has a near-tie to tip over. Per-run flip probability drops because fewer inputs are sitting where a flip is even possible.
This is necessary and it is not sufficient. Some inputs are legitimately ambiguous; no amount of prompt hygiene collapses a real 50/50 into a clean call. For those, you need a second mechanism that doesn't depend on the single sample being lucky.
Fix part two: self-consistency voting
The second fix is self-consistency — a known technique, not something I invented. Wang et al. introduced it in 2022 ("Self-Consistency Improves Chain of Thought Reasoning in Language Models") for reasoning tasks: sample several outputs and take the majority answer instead of trusting one. What's mine here is the diagnosis — recognizing that a flickering temp-0 classifier is a determinism problem a vote can stabilize — and the application to a structured flag pass.
The shape: run the flag classification N times in parallel, tally the results, and keep only flags that win a majority — at least 2 of 3. Temperature stays at 0 throughout. This is the actual voting structure from the tool, lightly trimmed:
const VOTING_RUNS = 3;
const MIN_VOTES = 2;
export async function flagsJD(extracted: ExtractedJD): Promise<Flag[]> {
// temp-0 is not deterministic (MoE routing, float non-associativity, batching),
// so run the flag pass N times in parallel and keep only flags that win a majority.
const runs = await Promise.all(
Array.from({ length: VOTING_RUNS }, () => runFlagPass(extracted)),
);
// Tally by severity + normalized concern. De-dupe within a run:
// one run = at most one vote per concern.
const tally = new Map<string, { votes: number; flag: Flag }>();
for (const run of runs) {
const seenThisRun = new Set<string>();
for (const flag of run) {
const key = `${flag.severity}::${normalizeForGrounding(flag.concern)}`;
if (seenThisRun.has(key)) continue;
seenThisRun.add(key);
const entry = tally.get(key);
if (entry) entry.votes++;
else tally.set(key, { votes: 1, flag });
}
}
return [...tally.values()]
.filter((entry) => entry.votes >= MIN_VOTES)
.map((entry) => entry.flag);
}
runFlagPass is a single openai.chat.completions.parse({ model: "gpt-5.4-mini", temperature: 0, ... }) call with a zod-validated structured response. (Each pass also drops flags whose evidence isn't a real quote from the JD — a separate grounding guard I'll cover another time. It's out of this snippet on purpose, so the determinism story stays clean.)
Two details worth pausing on.
Why it works. The per-run flip is independent noise — different batch composition, different reduction order each time. Independent noise averages out. A genuinely-clear flag wins all three runs and sails through; a genuinely-clean concern gets zero votes and never appears; a borderline flag that flickers might show up in one run out of three and gets correctly dropped below the threshold. A majority vote over independent samples is dramatically more stable than any single sample. That's the whole mechanism, and it's why the technique is old and boring and good.
The de-dupe. Note the seenThisRun set: within a single run, a concern can vote at most once. Without it, a model that listed the same concern twice in one response could carry a majority on its own — one run masquerading as two. The invariant I actually want is one run, one vote per concern, and that line enforces it. It's a small correctness touch, but it's the difference between counting runs and counting mentions.
Voting is not magic
Here's the part the snake-oil version of this post would cut, so I'll lead with it: self-consistency does not solve nondeterminism. It makes it improbable where it's already unlikely, and it does nothing for a true 50/50.
If a case is genuinely 50/50 — really on the boundary — three samples can split 2–1 either way, and the vote just relocates the coin toss to a slightly less likely place. Voting can't manufacture a decision the input doesn't contain. That's why you need both moves, not either alone: get the decidable cases off the boundary so the vote is rarely close, then vote so the residual wobble averages out. Part one shrinks the set of inputs where a flip is possible; part two stabilizes what's left. Skip part one and you're voting on knife-edges all day; skip part two and your clean cases still flicker.
And it isn't free. Three passes is roughly 3× the tokens and the latency of one. So you spend it deliberately — only on the step where a flip changes a decision. In this tool that's the flags, because a flag changing run-to-run changes whether I'd even open the role. The extraction and the score don't get the voting treatment; a one-point score wobble changes nothing I act on. Stability is a budget; spend it where a flip costs something.
The takeaway
temperature=0 buys you greedy decoding. It does not buy you reproducibility — that's a property of the serving stack, and on shared, batched, possibly-MoE infrastructure you don't control it. The variation isn't randomness; it's last-bit float noise tipping near-ties, which means it bites exactly at your decision boundaries and nowhere else.
So for any LLM step where a flip changes an outcome, design for stability instead of assuming the dial handed it to you: keep decidable inputs off the boundary, and vote where the decision is load-bearing. Temperature is a dial, not a guarantee — and knowing the difference is most of what shipping a reliable LLM classifier actually is.