The upgrade I was about to build
I have a small RAG pipeline I run as a prep project — Python, a Qdrant vector store, embeddings, cosine retrieval with a score threshold, and a grounded refusal when nothing clears the bar. It's built in the open: github.com/tp-coder/ai-eng-prep. Nothing exotic. The kind of thing you build to actually understand the moving parts instead of reading about them.
And I was about to add hybrid retrieval to it — vector search plus a keyword/BM25 leg, fused together. It's the fashionable upgrade. Every RAG best-practices post lists it. Pure-vector retrieval has a known weakness around exact terms and rare tokens, hybrid patches it, and reaching for it feels like the responsible senior move.
I had the branch in my head. Then I stopped and did the thing I actually believe in: I built the eval first. Before the feature. Not to prove the feature worked — to find out whether the feature was worth building at all.
It told me not to. And the why is the whole point of this post.
What the eval measures
The harness runs a set of labelled queries through the real retrieval path and scores two things every retrieval system lives or dies on:
- Hit@k — for a query, did the relevant document land anywhere in the top k results? It's a yes/no per query, averaged across the set. It answers did we retrieve the right thing at all.
- MRR (Mean Reciprocal Rank) —
1/rankof the first relevant document, averaged across queries. If the right doc is at rank 1, that query scores1.0. Rank 2 scores0.5. Rank 4 scores0.25. It answers how high did the right thing rank — not just whether we found it, but whether we found it first.
Hit@k is the coarse gate; MRR is the sharper instrument. You can pass Hit@4 while burying the answer at rank 3, and MRR is the thing that catches it.
The reciprocal rank itself is one line:
rank = first_relevant_rank(case, results) if case.should_find_relevant_context else None
reciprocal_rank = (1.0 / rank) if rank else 0.0
first_relevant_rank just walks the ranked results and returns the 1-indexed position of the first one whose source matches the labelled answer. No match, no rank, zero reciprocal rank. Then the aggregate is exactly as boring as it should be:
return {
"MRR": sum(relevance.reciprocal_rank for relevance in relevant) / relevant_count,
"Hit@1": sum(1 for result in relevant if result.rank == 1) / relevant_count,
f"Hit@{k}": sum(1 for result in relevant if result.rank is not None and result.rank <= k) / relevant_count,
"relevant_count": relevant_count,
}
That's the entire scoring core. The dataset is small and labelled by hand: five cases over a three-document corpus — three queries that should retrieve a specific note, and two unrelated questions ("best lasagna in Turin," "will it rain tomorrow in Madrid") that should retrieve nothing and trip the refusal. top_k is 4. The negatives matter as much as the positives: a retriever that confidently hands you context for a question your corpus can't answer is worse than one that finds nothing.
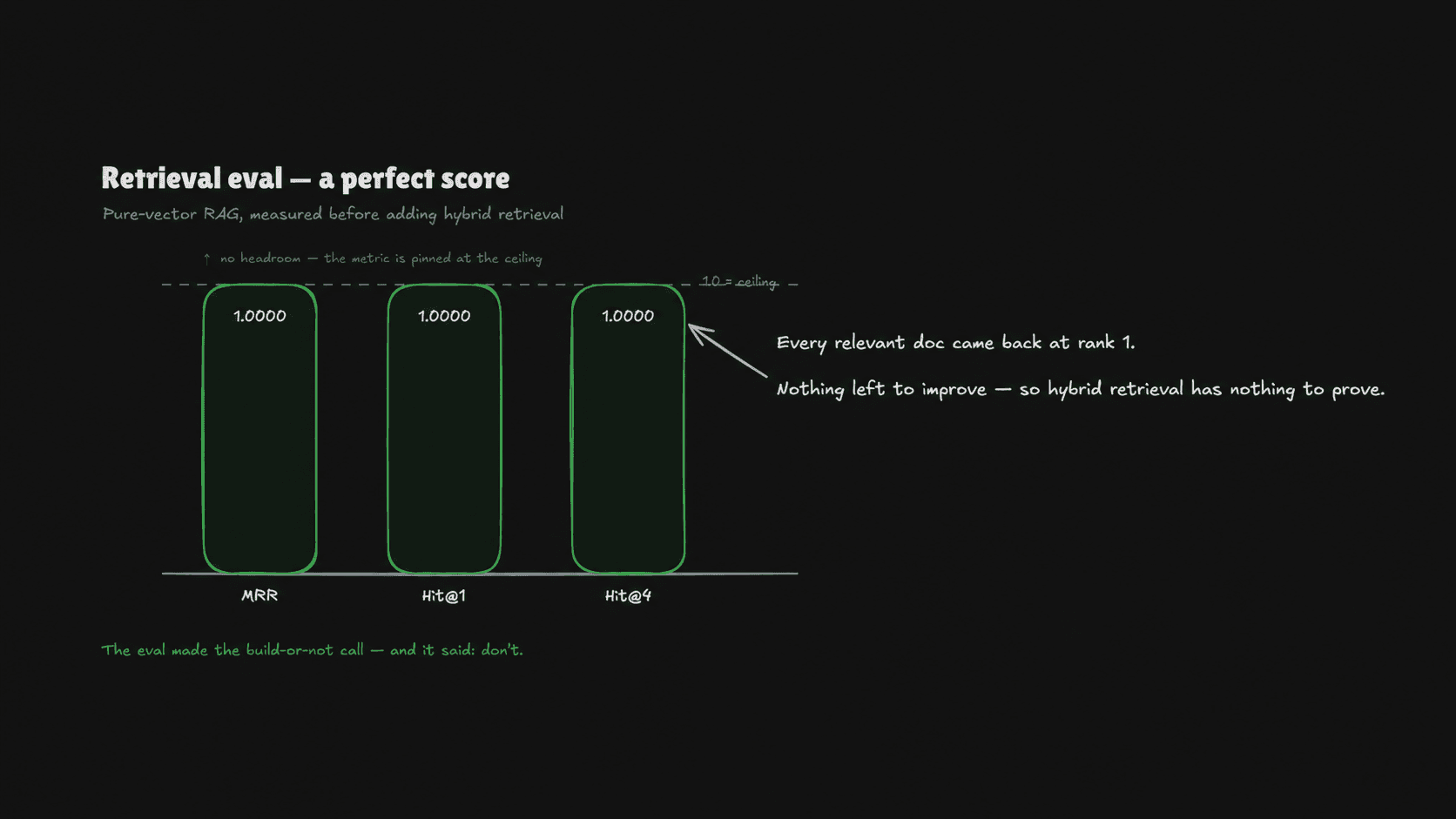
The result
I ran it expecting a baseline to improve on. That's the whole reason you build the eval before the feature — you want the before number so the after number means something.
Retrieval metrics (over 3 relevant cases, top_k=4) MRR=1.0000, Hit@1=1.0000, Hit@4=1.0000
Perfect. The right document came back at rank 1, every single time. Both negatives correctly retrieved nothing. There is no before number to improve on, because there's no headroom. MRR is already pinned at its ceiling.
And that quietly killed the feature. Here's the reasoning, in order:
You can't improve a metric that's already maxed. Hybrid retrieval's job is to rescue queries where vector search ranks the right doc too low or misses it. On this corpus, vector search never does that. So hybrid would add a second retrieval leg, a fusion step, and a pile of new failure modes — in exchange for an improvement I could not measure, because the number it would improve is already 1.0.
That's the trap. Not "hybrid is complexity." Complexity is fine when it buys something. The trap is complexity that buys something you can't see on your instruments. If I'd added hybrid here, I'd have shipped more code, more dependencies, and more surface area, and I'd have had no honest way to tell anyone — including myself — that it helped. The eval didn't just fail to justify the build. It made the justification impossible, which is a cleaner no.
Why it's perfect — and why that's the actual insight
Here's the part a worse version of this post would leave out, so I'll put it where it belongs, in the middle, in bold: this score is not a verdict on hybrid search. It's a fact about my data.
My corpus is three documents on three clearly different topics — a project overview, a note on structured outputs, a note on the RAG pipeline. Embeddings separate topics like that trivially. "Why does this project use structured outputs?" lands on the structured-outputs note by a mile, because nothing else in the corpus is even close in vector space. There's no near-duplicate to confuse it, no rare term that embeddings smear together, no keyword-shaped query that semantics fumble. The retrieval problem is easy, so a good-enough retriever solves it perfectly.
Hybrid retrieval earns its keep exactly where vector search stumbles: exact-match and rare terms (product SKUs, error codes, function names), keyword-shaped queries, and corpora full of near-duplicate-topic documents where two chunks are semantically almost identical and the keyword signal is what breaks the tie. My corpus offers none of those. It doesn't give hybrid a single chance to prove itself — not because hybrid is weak, but because my data never asks it the kind of question it's good at.
So "don't add hybrid" is the right call on this corpus, today. It is not "vector beats hybrid." Read it that way and you've learned the wrong lesson. The honest claim is narrower and more useful: my data doesn't yet contain the problem hybrid solves, so I have nothing to measure the upgrade against.
The real next step isn't the feature — it's a harder eval
If the eval is maxed and I still suspect hybrid matters, the move isn't to add hybrid and trust the vibes. It's to build a harder eval — one that contains the queries pure-vector should struggle with.
Concretely: add documents that overlap in topic but differ in detail, so the right answer isn't the obvious nearest neighbour. Add queries built around exact strings and rare tokens. Add the keyword-shaped questions semantic search is known to fumble. Push the corpus toward the shape where a vector-only retriever finally drops a rank or misses a hit — and watch MRR and Hit@k come off the ceiling.
Then hybrid has something to prove, and I have a baseline that can move. Add the feature, re-run the same harness, and read the delta. If MRR climbs, hybrid earned its complexity and I can say so with a number. If it doesn't, I just saved myself a dependency. Either way the data made the call, not the best-practices list.
That's eval-driven feature development: the eval defines what "better" means before you build the thing that's supposed to be better. The feature stops being a leap of faith and becomes a measured change against a fixed instrument.
The takeaway
An eval isn't a rubber stamp you bolt on after the feature to watch it pass. It's a decision instrument you build before the feature, so the data can tell you whether the feature is worth building.
Most teams add hybrid retrieval — or reranking, or a bigger context window, or any technique on the list — because it's best practice and everyone does it. That's how you accumulate complexity nobody can measure and nobody can remove. A good eval flips it: the burden of proof lands on the feature, and the only way past it is a number that moves.
It's the same discipline I wrote about with temperature=0 — measure, don't assume. There I refused to trust a dial that felt deterministic. Here I refused to ship an upgrade that felt responsible. Same reflex, pointed at a different comfortable assumption: build the instrument first, then let it decide. A perfect score that tells you not to build something is worth far more than a feature you can't prove helped.