The flag came back
Last week I wrote "temperature=0 Is Not a Promise". The short version: temperature=0 buys you greedy decoding, not reproducibility; on hosted, batched, possibly-MoE inference the logits wobble in their last bits and flip near-ties; and the fix is to get decidable inputs off the boundary and then vote — run the classification several times and keep the majority.
That post was right. It also taught me a reflex that, a week later, walked me straight into the wrong diagnosis.
Same tool — JD Analyzer, the little LLM pipeline I run for my own job search. Same symptom. A flag flickering on byte-identical input: one run it fires, next run it's gone, same paste, temperature: 0 everywhere. And by now I had a story for this. I'd written the story. Serving-stack noise tipping a near-tie. The cure is votes.
So I leaned harder on votes. The flag pass already runs five times and takes the majority. I checked the count was really five. I considered bumping it higher. I re-ran the eval — a modest thing, a handful of labelled JDs I trust, not a comprehensive suite — and the case kept splitting.
It kept flickering. More votes, same flicker. Which is the first thing that should have told me I was solving the wrong problem: voting is supposed to crush this, and it wasn't. When the fix you trust doesn't move the needle, the bug isn't where you think it is.
The reveal: the prompt was arguing with itself
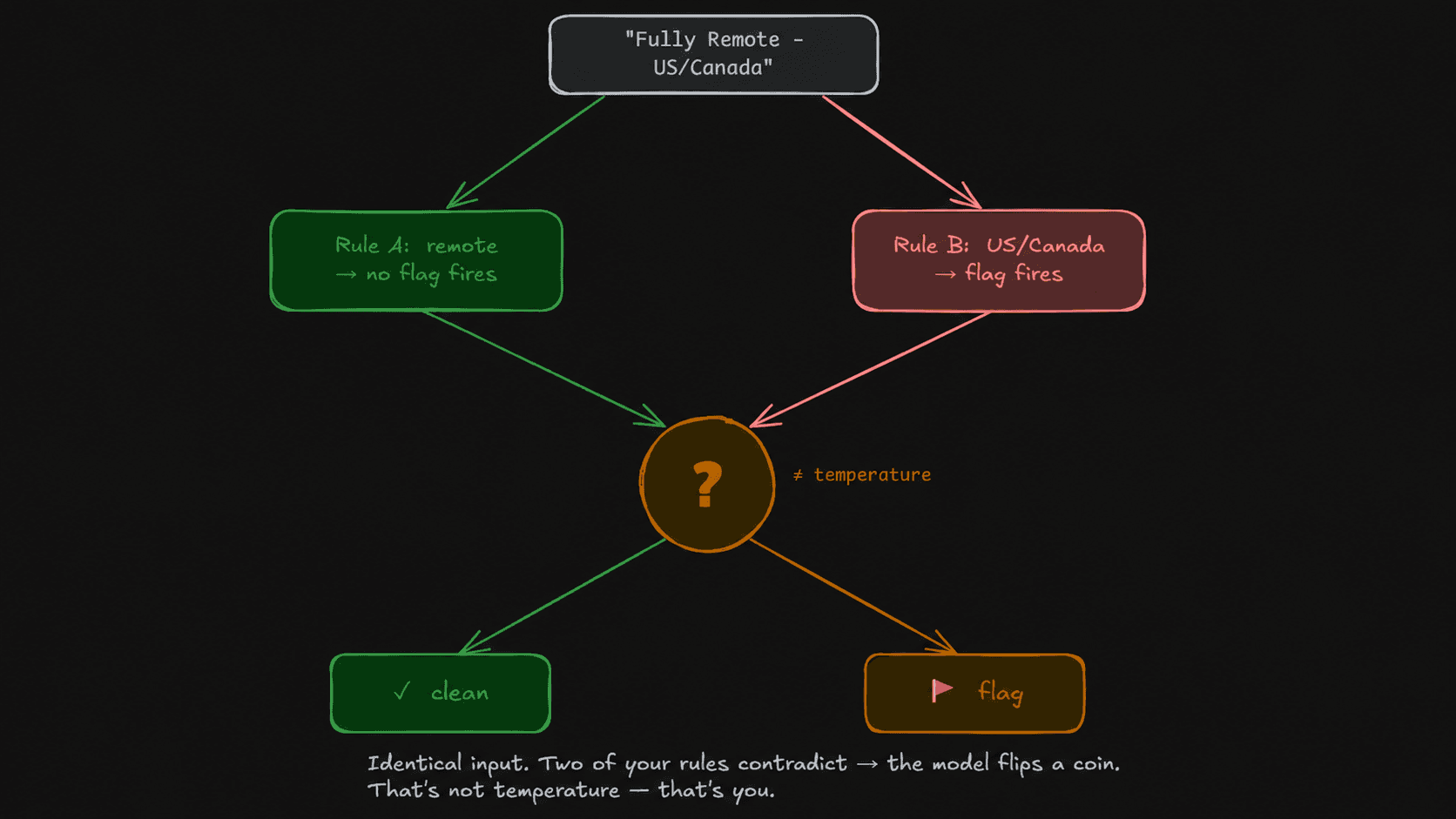
The flickering case was a real posting that said, near the top, "Fully Remote – US/Canada."
To understand why that broke things, you need two of my prompt rules. The classifier asks the model a set of grounded yes/no questions about the JD. Two of them were live here:
- A residency question: does the JD restrict this role to the US / Canada / North America? I'm in Madrid, so a North-America residency lock is a hard no.
- A remote question, whose intent was: is this on-site only? — because on-site-only in another country is also a hard no, but remote or hybrid is fine.
Here's the trap. Somewhere along the way I'd "cleaned up" the remote handling with a rule that read, in spirit, if the role is remote, it's not location-restricted. It sounds obviously true. It is obviously false. "Fully Remote – US/Canada" is remote and residency-restricted at the same time. Remote tells you nothing about residency — remote-from-where is the whole question, not whether remote is allowed.
So the JD satisfied both rules at once. One rule said remote, therefore no restriction fires. The other said residency is locked to North America, therefore the restriction fires. The model wasn't confused by the job description. It was holding two of my instructions that pointed in opposite directions on the same input, and picking one. Run to run, it picked differently.
That is not sampling noise. That is the model faithfully executing a contradiction I authored. The cleanup hadn't simplified the rule — it had deleted the one distinction that mattered: remote-from-where matters, not whether remote is allowed.
Why voting couldn't save me
Go back to the mechanism from the last post, because it's exactly what fails here.
Voting works because the per-run flip is independent noise — different batch composition, different reduction order, last-bit wobble tipping a near-tie a different way each time. Independent noise averages out. Run a decidable-but-borderline case five times and the true answer wins most of the runs; the wobble loses. That's the whole trick, and it's a good one.
A contradiction is not that. A contradiction is an intrinsic 50/50, not a noisy estimate of some true value. Both answers are equally instructed. There is no "correct" answer the model is approximating and occasionally missing — I told it X and I told it not-X with equal authority, so each run it picks one, and across five runs it just splits roughly down the middle. More votes don't converge on truth, because there's no truth in the input to converge on. They only relocate the coin flip to a slightly different place.
I flagged this exact failure mode in the last post and then forgot my own caveat:
Voting can't manufacture a decision the input doesn't contain.
The decision wasn't in the input. I'd removed it myself, with two rules that cancelled. The hero of the previous article — self-consistency, vote-it-out — is genuinely powerless here, and the culprit isn't the GPU. It's me.
The diagnostic tell
This is the part worth saving, because it's the cheapest test I know for telling these two cases apart.
"Fully Remote – US/Canada" is not ambiguous. A human reads it in half a second: yes, it's North-America-restricted. It is logically clear-cut. There's no genuine knife-edge in the content for last-bit float noise to tip.
So when a clear-cut case flickers, sampling noise can't be the explanation — because sampling noise only bites on near-ties, and this isn't a near-tie. Something is manufacturing a tie that the input doesn't contain. That something is almost always your prompt: a contradiction, or a rule sloppy enough that the model can read it two ways.
When a logically clear-cut case flickers, suspect your prompt before the GPU.
The last post's tell was "why is this input sitting on the knife's edge?" This post's tell is sharper and comes first: "is this input even supposed to be on the knife's edge?" If a case any reasonable human would call instantly is flipping run-to-run, you don't have a serving-stack problem. You have a logic problem wearing a serving-stack costume.
Three nondeterminisms that look identical in the output
Here's the trap underneath all of it: these failures produce the same symptom. A flag that appears and vanishes. You cannot tell them apart by staring at the output, and they need opposite fixes.
1. Sampling-noise flicker. The real thing from the last post. The input is decidable but sits near the boundary, and last-bit float wobble on shared inference tips it. Fix: get the case off the boundary (tighten the rule, sharpen the question) and vote so the residual wobble averages out. Voting helps.
2. Contradiction flicker. The input is clear-cut, but two of your rules adjudicate it in opposite directions, so the model coin-flips your own logic. Fix: remove the conflict. Voting is useless — there's no true answer to average toward. This is the one I'd just lived.
3. Genuine-ambiguity flicker. The input itself is a real 50/50 — a JD that honestly straddles two categories, where two careful humans would disagree. Fix: irreducible at the prompt level. You mitigate (pick a tie-breaking convention) or move the decision into code where you can make the call explicit. Voting can't help, but for an honest reason this time: the ambiguity is in the world, not in your prompt.
The skill is not "fix flicker." The skill is telling which flicker you have, because reaching for votes on a contradiction is exactly as wrong as reaching for a prompt rewrite on pure float noise. Same symptom, three causes, three different moves.
The whack-a-mole trap
I fixed the contradiction. Then I learned why fixing contradictions one at a time is a losing game.
A different flag is meant to fire on coordination-heavy roles — PMO / TPM work with no hands-on engineering, which is off my lane. It started firing on a JD that was clearly an IC build role, snagging on the phrase "interact with other functions." Sounds coordination-y. Isn't. So I patched the rule to not count that.
The model immediately re-fired the same flag on the next phrase: "lead a team of 4+ and own their roadmap." Also sounds coordination-y. Also, in context, a senior IC who builds and leads — exactly the kind of role I want.
I could have banned that phrase too. And the model would have found the next one. You cannot enumerate your way out of this — a prompt that's a blocklist of suspicious phrases is playing a game the model will always out-stack you at, because there are infinitely many ways to phrase "leads people while also building." Keyword-spotting in prose loses. The real fix wasn't another banned phrase; it was changing the question — is coordination the primary function, rather than building? — so that "leads a team while building" answers no on its own, by construction, no enumeration required.
The durable cure: facts in the LLM, gates in code
The deeper problem behind all three flickers is that I was asking the model to do two different jobs in one breath: read the JD and apply my hiring logic — and apply it consistently, in prose, run after run. The first job is its strength. The second is where determinism is supposed to live, and prose is a terrible place to keep an invariant.
So I stopped adjudicating in the prompt. The architecture now splits cleanly:
- The LLM answers facts — crisp, grounded, independent yes/no questions about the JD. Does it restrict residency to North America? Is it on-site only? Is coordination the primary function rather than building? Each fact carries a verbatim quote from the JD as evidence. That's the model doing what it's good at: reading.
- Code applies the gates. Plain TypeScript takes the facts and decides which flags fire.
if (restrictsResidencyToNA) → red.if (!hasHandsOnBuildWork && isPrimarilyCoordination) → red. The hiring logic lives inifstatements, where it belongs.
What this buys is structural, not cosmetic. A contradiction becomes impossible to write: code can't silently say X and not-X — if two gates conflict, that's a visible bug in a function I can read and test, not a coin flip buried in a paragraph. The model is no longer being asked to honor an if. It just reports what the JD says; the if is an actual if.
Voting moved too, and got better for it. It now happens at the fact level: extract the facts five times, majority-vote each individual boolean, then derive the flags once from the agreed facts. A crisp yes/no like "does it restrict residency to North America?" is far more stable to vote on than a holistic "should this flag fire?", because the fact has a real answer the votes can converge on — exactly the condition voting needs.
One more guard worth a sentence. A fact only counts as true if its evidence is a real contiguous quote from the JD — checked in code against the source text. So a run that hallucinates a plausible-sounding fact can't flip a gate; an invented quote isn't found in the JD, the fact is discarded, and the gate never sees it. Grounding and gating reinforce each other: the LLM can only assert what it can quote, and only quotable facts get a vote.
The takeaway
temperature=0 isn't deterministic — that was the last post. But the sequel is the part that actually bit me: not all of your nondeterminism is temperature. Some of it is a contradiction you wrote, faithfully executed.
The two cases look identical in the output and need opposite fixes. The cheap test that separates them: does a logically clear-cut case flicker? If yes, suspect your prompt before the GPU. And the cure for a contradiction is never more votes — voting averages noise, and a contradiction isn't noise. The cure is to remove the contradiction, and ultimately to move the decision out of the prompt and into code, where an if can't quietly say X and not-X. Let the model read. Let the code decide.