Most LangGraph content shows you how to build an agent. The more useful question is when not to.
There is a lot of writing on how to wire up a graph, add a tool, give the model a loop, and let it run. Much less on the decision that comes first: does this workload actually need a framework, or am I about to add an abstraction I will have to maintain forever to solve a problem a plain function already solves?
That second question is the one that separates people who have operated LLM systems from people who have followed a tutorial. So I want to work through a concrete case where I reached for LangGraph, looked at what it bought me, and concluded — for that shape — almost nothing. And why that conclusion is the point, not an anticlimax.
The case: a pipeline that already worked
The system is JD Analyzer, a small LLM pipeline I run as part of my own job search. You paste in a job description and it returns a structured fit analysis: extracted fields, a score across several dimensions, a set of risk flags with evidence, and a synthesized verdict.
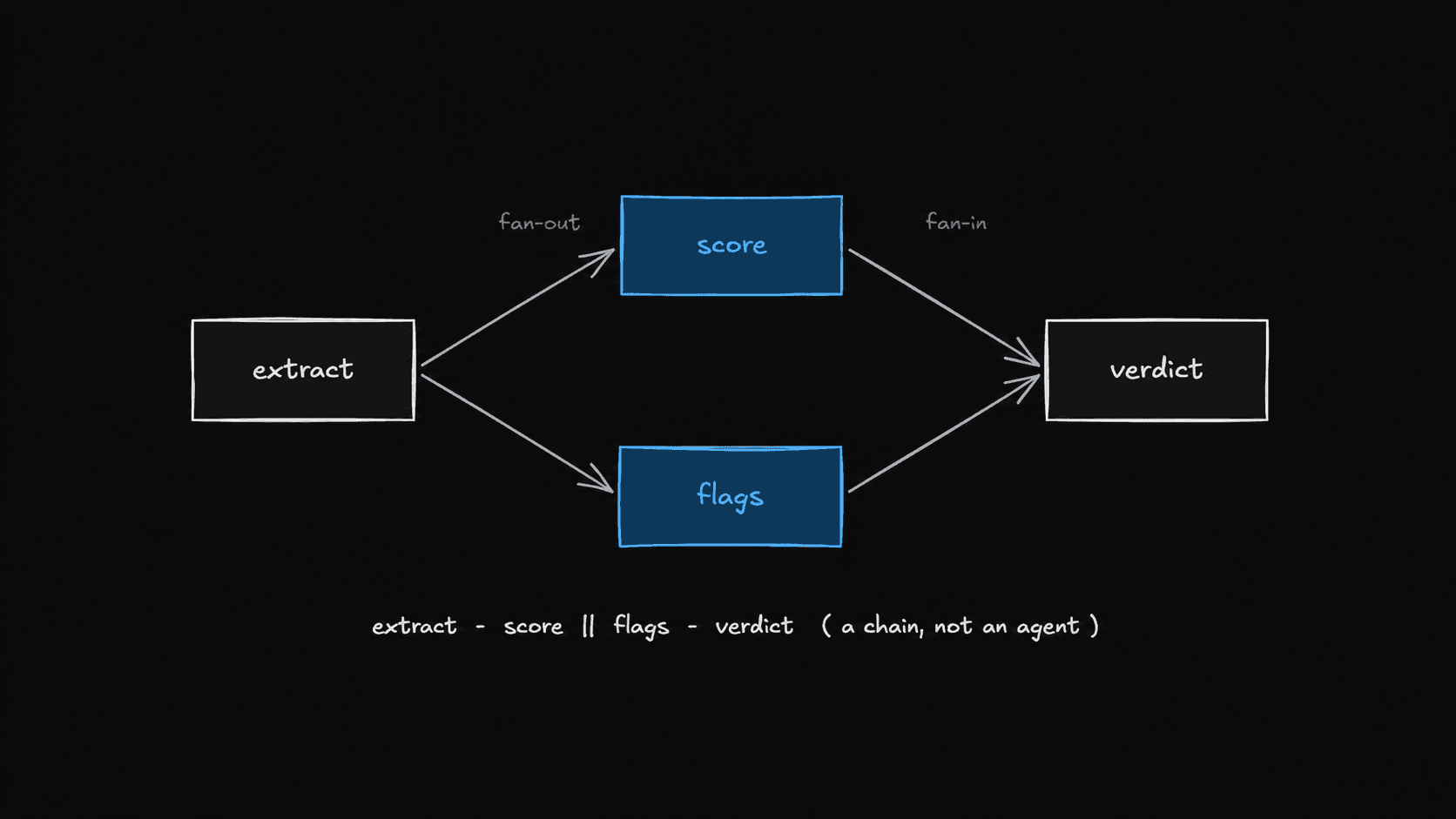
The flow is four steps: extract the JD into structured fields, then score and flag in parallel, then synthesize a verdict from all three. Each step is one LLM call with a system prompt and a zod-validated structured output. Nothing exotic.
The original orchestration was a hand-rolled chain. It is short enough to read in full:
async function analyzeJD(jdText: string): Promise<Analysis> {
const extracted = await extractJD(jdText);
const [score, flags] = await Promise.all([scoreJD(extracted), flagsJD(extracted)]);
const verdict = await synthesizeVerdict(extracted, score, flags);
return { verdict, extracted, score, flags };
}
That is the whole thing. Extract first, fan two calls out with Promise.all, wait for both, synthesize. It is deterministic, it is legible, and a new engineer understands it in about ten seconds. It has no framework dependency.
I refactored it into a LangGraph.js StateGraph — not because it was failing, but to see what the framework actually buys for a workload this shape. The honest answer turned out to be: for this shape, very little. That is worth saying out loud, because the more common move is to adopt the framework first and rationalize it later.
Chain versus agent: the distinction that decides this
The word "agent" gets thrown at anything with an LLM in it, which makes it useless for actual decisions. The distinction I care about is narrow and load-bearing:
- A chain is a flow the developer hardcodes. The control flow is fixed and known at build time. The model fills in steps; it does not decide what the steps are.
- An agent is a flow where the model decides the control flow — which tool to call, whether to loop, when to stop. The path is decided at runtime, by the model.
JD Analyzer is a chain, deliberately. The sequence — extract, then score and flag, then synthesize — is fixed. The model never chooses the route. It does bounded, structured work at each fixed node and nothing else.
That is a design choice, not a limitation I have not gotten around to fixing. It lines up with a stance I have written about elsewhere: reliability comes from governed, known flows, not from handing the model more rope and hoping. A fixed DAG is something I can reason about, test, and trust. An agent that re-plans its own route is a different and larger risk surface, and I take that on only when the problem genuinely requires it. This one does not.
The one-to-one mapping, and the gotcha
Porting the chain to LangGraph was almost mechanical, which is itself the finding.
The node functions did not change at all. extractJD, scoreJD, flagsJD, synthesizeVerdict stayed exactly as they were — same prompts, same zod schemas. LangGraph orchestrates them; it does not replace them.
The Promise.all([scoreJD, flagsJD]) became a fan-out: two edges leaving the extract node. The implicit "wait for both, then synthesize" became a fan-in: two edges arriving at the verdict node, which LangGraph joins for you. You no longer write the await — the graph knows the verdict node runs once both inbound edges have resolved. That is the one genuinely nice thing: the join is declared by the graph's shape rather than spelled out in control flow.
It is also, for four nodes, a wash. Promise.all already expressed that join in one line that any JavaScript engineer reads instantly. Trading a one-line Promise.all for a graph definition, a state-channel schema, and a framework dependency is not obviously a win at this size.
And then the gotcha, which is the kind of thing you only hit by actually building it:
In LangGraph, node names live in the same namespace as your state channels. If you name a node the same as a state key, it throws.
I had named my state channels score, flags, and verdict — the natural names — and then tried to name the nodes that produce them the same thing. Collision. The graph would not compile. The fix is trivial once you understand the cause: rename one side so node identifiers and channel keys do not overlap (scoreNode producing into the score channel, and so on). Five minutes. But it is exactly the kind of seam that does not show up in the quickstart and does show up the moment you build something real. Concrete gotchas like this are how you tell work that was done from work that was read about.
When LangGraph does earn its weight
None of this is an argument against the framework. It is an argument for adopting it when the workload crosses a threshold, and being honest that a four-node DAG has not crossed it.
Here is the threshold I actually use. Reach for LangGraph when you need one or more of these, and a hand-rolled chain would mean rebuilding them yourself:
- Checkpointing and resume. Persist state between nodes so a long or expensive run can survive a crash, a restart, or a deploy and pick up where it stopped instead of re-running from the top.
- Human-in-the-loop. The
interruptprimitive lets the graph pause, surface state for a human decision, and resume with that input threaded back in. If a human approval belongs inside the flow, this is real leverage. - Streaming intermediate state. Emitting progress as each node completes, rather than only the final result — for UIs where the user watches the work happen.
- Tracing and evals. LangSmith integration for inspecting runs, debugging failures, and evaluating quality over a set, which matters once you have more than a handful of cases to keep honest.
- Dynamic and conditional branching. Routing that depends on a node's output — a conditional edge that sends the flow one way or another at runtime. This is the door to actual agentic behavior, where the model influences the path.
The clean rule underneath all five: reach for LangGraph when the flow stops being a fixed DAG — when it needs to persist, pause, stream, be evaluated at scale, or branch on its own outputs. JD Analyzer needs none of those today. It is a short, fast, deterministic pipeline that runs in seconds and is cheap to re-run from scratch. Adding a graph engine to it buys a cleaner fan-in and costs a dependency, a state schema, and a naming gotcha. For now, the chain wins.
If the tool grew an approval step before it acted on a verdict, or a resumable batch mode, or conditional routing based on a JD's shape, the calculus would flip — and I would reach for the framework without hesitation. The point is not that LangGraph is heavy. The point is matching the tool to the workload instead of to the trend.
Knowing when not to add the abstraction is the senior move
It is easy to demonstrate that you can use a framework. It is more useful to demonstrate that you know when not to. Every abstraction you add is something you, or someone after you, has to understand, maintain, and debug at 2 a.m. The bar for adding one should be a real need, not novelty.
I make this call per use case, not out of a preference for one mode over the other. The same week I kept JD Analyzer as a deterministic chain, I was operating a genuinely agentic multi-agent setup day to day — specialized roles, delegation, controlled handoffs, human approval at the meaningful points. So this is not a chain-versus-agent purist arguing from one side. It is choosing the boring orchestration here on purpose, because the workload is a fixed DAG, and choosing the heavier machinery where the workload actually earns it.
Both are the same instinct: match the structure to the problem, and do not add control flow the problem does not ask for. Knowing where that line sits — and being able to say "a framework would be overkill here" with a straight face — is most of what senior judgment in this space actually is.